


Are social media undermining democracy? From algorithms to complexity
What we (don't) know about the role of socio-technical systems in shaping human behavior


The community of Computational Social Science has been just shaken by the simultaneous publication of four seminal papers, reporting the outcome of an historical collaboration between industry and a pool academic partners.
In the following, I will describe some background about the field, based on my own experience (it seems yesterday, but it’s 11 years to date from the very first paper), and then move to summarize the main findings of the studies. Finally, I will discuss the ongoing debate emerged in the community, concerning the collaboration protocol, the data availability and the interpretation of the results.
#ComplexityThought is slow reading: take your 15 minutes to enjoy this post. In this short journey, you will also find comments from other experts in the field, including one of the authors of the studies, who kindly accepted to answer my questions in less than 24h.
The not-so-hidden power of social media
It was a day of June 2012 in a (not so sunny) Birmingham, UK, when I was having a beer with a younger colleague (and later good friend, Antonio Lima, now Senior Research Scientist at Spotify), while discussing about the necessity to study online social networks to better understand human behavior. Antonio was pretty good in collecting social media data, especially from Twitter (when I barely had an account).
However the major issue of the social events which are interesting to analyze is that usually you start to gather data after they happen, for well obvious reasons. The standard approach is to collect data back in time, using the tools provided by platforms (APIs): given some parameters, acting as filters (range of dates, keywords, etc) one can ask platforms to download their recorded social activity. The major drawback of this approach is that one usually does not get the whole data about an event, for several technical and less technical reasons. Fortunately, another possibility is to gather data in real time, while an event is unfolding: the main drawback of this approach is that one has to know in advance when and where. Obtaining this information in advance for an event of public interest worldwide is, to say the least, unlikely. Imagine to know in advance when and where the next riots would be, or where the next protest of global interest will happen.
At that time I had still several contact with the community of high-energy physics, and I listened to some interesting rumor: people at CERN were going to make a huge announcement on the 4th of July 2012. Discussing with Antonio, we made a guess: it could be the discovery of the Higgs boson, the famous “God particle”. Antonio set up the machinery to gather the data some days before the announcement and we started to wait for it. On the 4th of July we were following the conference in real time and were astonished to learn that our guess was correct: it was tantalizing to see, in nearly real time, how that event triggered a huge collective attention wave on Twitter lasting for days. We were collecting almost 1 million tweets about the Higgs boson in a few days, with a participation rate jumping from ~1 user/min to 519 users/min.
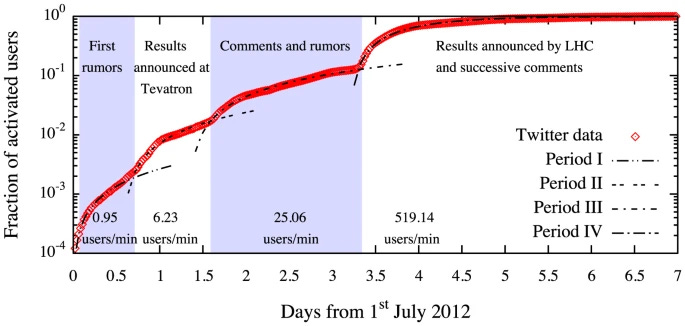
The analysis of that data (now publicly available) was so fun and unraveled so much information: we were able to measure quantitative changes in human collective behavior before, during and after a major exceptional event.
In the last decade, the interest in social media analysis literally exploded, with thousands of papers — analyzing so many aspects of online social networks — that is complicated even to stay up to date with the literature. This literature is now a solid ground for part of Computational Social Science. A manifesto of the field, from 2012, describes it as follows:
“The increasing integration of technology into our lives has created unprecedented volumes of data on society’s everyday behaviour. Such data opens up exciting new opportunities to work towards a quantitative understanding of our complex social systems, within the realms of a new discipline known as Computational Social Science. Against a background of financial crises, riots and international epidemics, the urgent need for a greater comprehension of the complexity of our interconnected global society and an ability to apply such insights in policy decisions is clear. This manifesto outlines the objectives of this new scientific direction, considering the challenges involved in it, and the extensive impact on science, technology and society that the success of this endeavour is likely to bring about.”
The potential of social media to influence human behavior can have a huge impact on our society, from public health to democracy. From coordination during the arab spring to the proliferation of disinformation during the COVID-19 pandemic, governments and companies are well aware of the (dark) power of social media for spreading misinformation and manipulation. In the era of automation, the algorithms used by social media platforms to engage users and the rise of social bots amplified the power of a few in shaping the opinions of many, leading to the emergence of polarization, infodemics or personalized targeting to sustain conflicts, often by means of low-credibility content.
If you can measure it and understand how it works, you can try to control it!
It’s in this context that, in 2018, the New York Times reported that at least 50 million Facebook users were affected by the activities of a company, Cambridge Analytica, during the 2016 US Elections. That was, to my memory, the largest scandal in the social media universe, ever.
“Wired to split”
Even if you are not a computational social scientist, almost surely you have read something about the recent publication of four papers: the outcome of an important (and unprecedented) collaboration between Meta and a selected pool of academics. The goal of the collaboration was to define the role of Facebook and Instagram algorithms in “seeding of deep divisions during the 2020 US presidential election”.
The introductory piece to the Science special issue catches the attention with a simple, yet powerful, question:
“Can a business model that prioritizes “engagement algorithms”
pose a threat to democracy?” — E. Uzogara
Let’s summarize the main findings below.
Paper #1: Asymmetric ideological segregation in exposure to political news on Facebook
In their quest to uncover the (hidden) dynamics of political news consumption on Facebook during the 2020 US election, the researchers delved into the vast ocean of data from 208 million American users. They embarked on a journey to understand the intricate interplay between users' potential exposure and their actual engagement with news content.

The findings were fascinating. Ideological segregation emerged as a powerful force in the Facebook infosphere. Conservative and liberal audiences exhibited a striking asymmetry, with conservatives inhabiting a unique corner of the news ecosystem. Within this conservative stronghold, misinformation reigned supreme, as flagged by Meta's own fact-checking program.
But how did this separation come to be? The authors pointed their lens at Facebook's own Pages and Groups, where the seeds of segregation were sown. The curators shaped the flow of information, guiding users towards ideologically congruent content. The allure of Pages and Groups was kind of magnetic, drawing like-minded users together in a network of shared beliefs.
The study highlighted the symbiotic interplay of algorithmic and social forces, where ideological alignment and content amplification played their parts. Yet, questions remained: what other influences lurk within Facebook's underlying social graph? Will the observed segregation persist over time or evolve into something else?

The researchers recognized the limitations of their exploration, acknowledging the need to peer deeper into the vast richness of online content. They called upon future research to venture beyond the analysis of URLs and domains, exploring the uncharted realms of non-URL content for a more comprehensive understanding of online human behavior and other sources of segregation.
Surely, these findings hold implications for our democracy's equilibrium. Transparent and accountable research practices illuminate the journey to better understand the vast landscape of social media's influence on our political mind.
Paper #2: How do social media feed algorithms affect attitudes and behavior in an election campaign?
Another task explored the effects of social media (Facebook and Instagram) feed algorithms during the 2020 US election. Their study unravels how these algorithms (might) shape people's attitudes and behaviors.
The findings were unexpected, at first sight, especially since previous studies have found that “simple filtering algorithms might be powerful tools to regulate opinion dynamics taking place on social networks”.
By flipping the script and using a reverse-chronological feed, the authors observed some major changes in users' virtual experiences. Time spent on the platforms decreased, and engagement took a hit too. But here's the kicker: the content landscape shifted too. Users got served more political and sketchy content, while the “not-so-nice stuff” decreased on Facebook. Plus, they found themselves mingling more with moderate pals and diverse sources.
Now, here's the intriguing part. Despite all these on-platform shake-ups, the reverse-chronological feed surprisingly didn't change much political attitudes, issue polarization, or political knowledge during the three-month study.
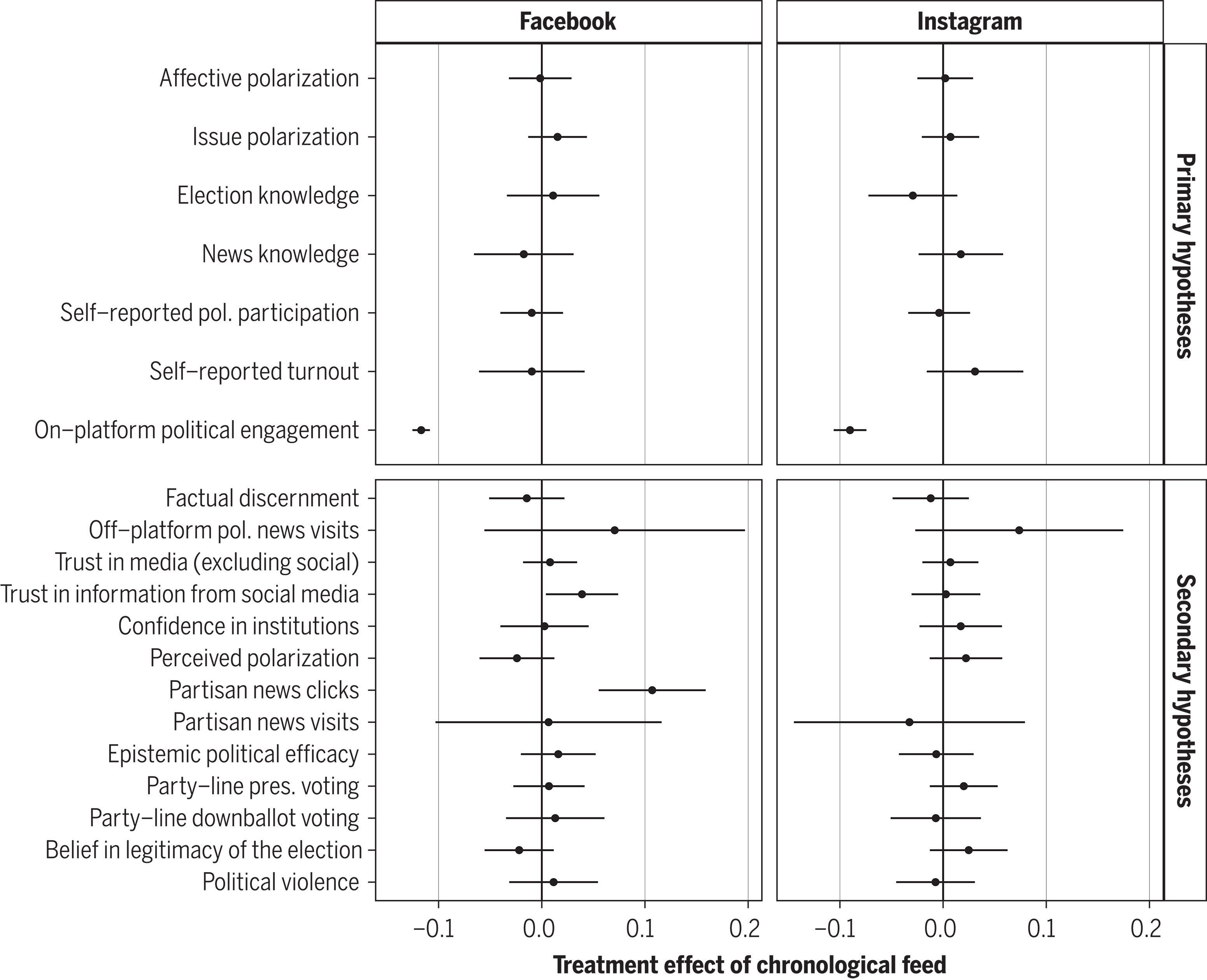
The study tested three primary hypotheses, looking into polarization, political knowledge, and political participation. While online political engagement took a dip, there weren't any significant shifts in offline behavior or political attitudes. These findings throw some shade on common beliefs about how social media algorithms influence politics and elections.
The study has its limits, like the need for a longer intervention period and the influence of specific political contexts. It also hints at the complexity of algorithmic effects, suggesting they might be mingling with other factors in unintended (mysterious?) ways.
Therefore, the study is not definitive about the impact of social media exposure on human behavior: it is not yet clear how online forces – emerging from user-to-user interactions, collective attention, infodemics, etc – affect society at large. So, we're still left with more questions to explore in these largely uncharted territories.
Paper #3: Reshares on social media amplify political news but do not detectably affect beliefs or opinions
This paper examined the role of reshared content during the 2020 US election. The research team split users into two groups: one group got the usual feed with reshared content, while the other group took a break from all the resharing for three months.
Remarkably, removing reshared content had some significant effects. Users in the No Reshares group saw way less political news, especially from unreliable sources. Clicks and reactions on posts also dropped a bit while, surprisingly, users' own resharing behavior remained pretty much unchanged. Seems like most reshared content doesn't go viral; it's a mix of the good and not-so-good stuff getting more exposure.
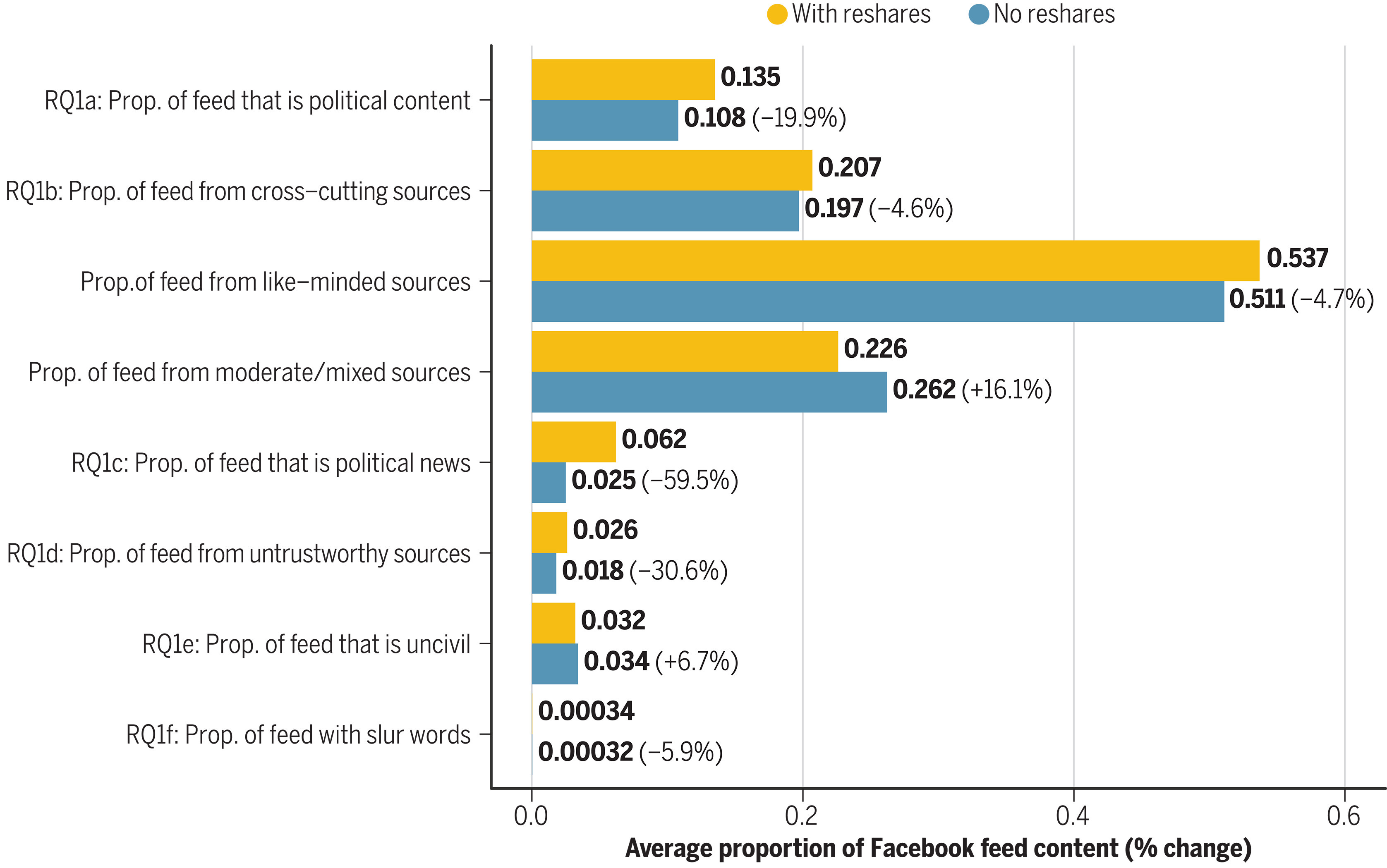
One might think this would change people's political attitudes and behaviors, but it was not the case. Despite these changes, no evidence for any big shifts in political beliefs or actions: overall, resharing didn't have a massive impact on political attitudes or offline behaviors.
Also in this case there are some limitations: the experiment run during a politically charged period in American history, so the results might be influenced by the context. Moreover, it is not guaranteed at all that the result would replicate in other countries, for instance in the EU zone. As Sander van der Linden — Director, Cambridge Social Decision-Making Laboratory — told me: “what I heard from Francis Haugen, is that Facebook had already taken down the most severe election-related misinformation by the time the experiment was ran and users had already joined relevant FB groups so maybe the potential for change was already extremely limited at the outset of the experiment”.
Paper #4: Like-minded sources on Facebook are prevalent but not polarizing
In this last paper, the authors investigated the prevalence of “echo chambers” on Facebook during the 2020 US presidential election. Among all active adult users, the platform was dominated by 'like-minded' content.
The authors conducted an experiment with 23,000 users. A shift in the Facebook algorithm reduced exposure to like-minded content, dimming the glow of engagement and uncivil language. Yet, despite this relevant intervention, the political attitudes of users remained unchanged, suggesting that Facebook might just reflect our own essence rather than shaping new behavior.
“We found that the intervention increased their exposure to content from cross-cutting sources and decreased exposure to uncivil language, but had no measurable effects on eight preregistered attitudinal measures such as affective polarization, ideological extremity, candidate evaluations and belief in false claims” — B. Nyhan et al
The debate
Reactions from academics and practitioners quickly filled — guess what? — social media.
“Facebook may have already done such an effective job of getting users addicted to feeds that satisfy their desires that they are already segregated beyond alteration” — H. Holden Thorp
On the one hand, a current of researchers claiming that the four studies provide the missing evidence that online social networks do not influence human behavior. On the other hand, a current thinking that the results are interesting and needed, but not enough to support that claim. A general consensus emerges about the research model and the data access.
Pierluigi Sacco — leading expert in studying culture as a driver of social impact and behavioral change — told me: “What we are learning from the study of infodemics is that people are often simultaneously active on several platforms and have access to online content from multiple digital and offline sources. Moreover, their beliefs and convictions are positioned on a complex topical where opinions on apparently unrelated issues such as pandemics, global climate change, and the Russian-Ukrainian war are often strongly correlated. Can we really appreciate how exposure to online content on a specific platform for a limited time can influence the dynamics of attitudes and behaviors in such a socio-cognitive landscape? It is more or less like trying to infer the global structure of a function of many variables from a couple of partial derivatives.”
“Simply put, researchers don't know what they don't know” — M. Wagner
There are several points that should be further discussed, although this post is already long.
The model: Independence by permission. In his report, Mike Wagner — chosen as independent observer to monitor the activities of the teams — comments “A success, but not a model”. See also this comment on Twitter by Eleonora Benecchi.
“My conclusion is that for social science research about the effects of social media platforms and their use to be truly independent, outside academics must not be wholly reliant on the collaborating industry for study funding, must have access to the raw data that animates analyses, must be able to learn from internal platform sources about how the platforms operate, and must be able to guide the prioritization of workflow. Additionally, some project structures that were appropriate to US-based faculty are unlikely to apply to other parts of the world.” — M. Wagner
The limited access to raw data. Raw data were not available even to the researchers involved in the study. For the other researchers, the access is limited to replicate the main results. While caring about privacy is more than welcome, this approach cannot become a standard for industry-academic collaborations. Indeed, researchers should be free to generate their own research questions and find an answer, otherwise the perimeter of these studies will remain limited.
Inferring causal forces. Kai Kupferschmidt, in this piece, digs into some of these problems. I fully endorse some of the quotes found there, where even the authors of the studies agree that we should avoid to amplify the results beyond their limited context:
“No one is saying this means that social media has no negative effects,” says Brendan Nyhan, a political scientist at Dartmouth College and one of the researchers involved. “But these are three interventions that have been widely discussed and none of them measurably changed attitudes. So, I think that that tells us something.”
David Garcia — lead of the Computational Social Science Lab at the U. of Konstanz — might have provided an overall take home message:
It is important to distinguish between what may have caused polarization and what we can do about it, says Garcia. “The results of these experiments do not show that the platforms are not the problem, but they show that they are not the solution.”
In an interesting thread on this matter, Joe Bak-Coleman reports that “The content they *do* view is shaped by all of the dynamics among the vast majority of users who are not in the treatment group. Any causal echo-chamber like effects can sneak through just fine here”, which is perfectly aligned with the way I interpret the overall results.
Sander van Der Linden has told me: “I respect the difficulty of engaging in this kind of research partnership, the data are massive, and the results are interesting but nonetheless limited in terms of what we can conclude”. As an expert, he identified specific weakness in the choice of the experimental setup — that, IMHO, might also be due to limits imposed by Meta: “It's also not clear to me that the chronological feed is the right control condition. They should have tested these results against one of the recommendations which I and other researchers have made to Meta before, which is to downrank toxic and polarizing content, as this is a treatment more directly related to polarization. There's a lot of noise in the behavioral data so you need a treatment that acts more directly on the variable of interest (e.g., reducing polarizing or extremist rhetoric)”.
I have asked Sandra Gonzalez Bailon — one of the authors involved in the joint research team and Director of the Center for Information Networks and Democracy at the University of Pennsylvania — what’s the main strength and weakness of the four published papers in the context of social media analysis and what she thinks about the report of M. Wagner. She says: “The question “is social media destroying Democracy?” is a very complicated question that requires modular answers. We think of these 4 studies (and the 12 that are currently in the publication pipeline) as important pieces in a complex puzzle. The hope is that, by putting these pieces together, we can offer a more informative picture that feeds into ongoing conversations and unprecedented evidence that contributes to public knowledge. We also hope that this research demonstrates the value of allowing external researchers to access proprietary data (with strong provisions to protect privacy and anonymity) because, as we acknowledge in the articles, our results are contingent to a particular time and a particular place. The scientific community needs to be able to replicate these studies, and conduct new ones, in other social and political contexts. And for that, data access needs to be the rule, not the exception”.
She adds: “It was our idea to bring an external, independent rapporteur into the project because we wanted to have as many mechanisms of transparency as possible. We all appreciate the time and effort that Mike put into documenting this unprecedented collaboration. There is a very interesting ‘sociology of science’ aspect to his writing that I think is invaluable. We, the academic researchers, truly believe that we have moved the dial toward greater transparency (definitely compared to past research): we have established a set of processes and quality checks that allowed this very complex collaboration, with many moving pieces, to succeed in yielding peer-reviewed publications. But we also agree with the message that this collaboration should be the first steppingstone in ongoing efforts to open data access to more researchers. We think of this project as a proof-of-concept, not as the final answer to all questions, and this is compatible with what Mike argues in his piece.”
Therefore, Sandra and other authors, as well as a representative component of the Computational Social Science community, are aligned with the main points of this (long) essay. This is reassuring, since it demonstrates that the field is compact in recognizing the common challenges and the current value of industry-academic collaborations, as the one between Meta and our US colleagues.
From the outset, it is crucial to recognize that algorithmic influence represents merely a fraction of the multifaceted causal factors that empower social media to mold human behavior. Online social networks are interconnected and complex socio-technical systems where emergent collective dynamics intertwine with individual behaviors in ways that are still poorly understood.
“People seem to suggest this is somehow evidence against the fact that Facebook and its algorithms causes polarization. I think it's premature to say anything about this given that only one alternative feed was tested, the time period was specific and limited, and to really answer that question, we should look at historical FB data on ideological segregation since the launch of FB and model its trajectory and change over time as a function of system dynamics.” — Sander van der Linden
I fully agree. The unpredictability of this intricate interplay underscores the challenges in fully comprehending the transformative impact of social media on our lives.
I like the story about the 'God particle', so cool! It's very comfortable to read the whole post and I learned a lot!
I'm curious about the methodology evolution behind these works. Before the 'God particle' story, as you said, researchers usually gather data back in time and then analyze the data, In your 'God Particle' story, you can gather some real-time data and analysis. And in the following 4 papers, we see researchers were even doing more like 'dividing people into two groups and showing them different information'. WOW, how did the do that? Are the researchers collaborating with Facebook and they changed the recommendation algorithm for Facebook to manipulate what people see? or do They use some bot to show information to people?
Overall it seems that we can not only gather data and analyze data, but now we are able to conduct more experiments by perturbing social media. I'm very curious about How and to what extent can we perturb and what is the limitation of perturbation?
Thanks again, it's a very informative post!
Well, it is also "still poorly understood" whether it is meaningful to think of online social networks as "interconnected and complex socio-technical systems where emergent collective dynamics intertwine with individual behaviors." If anything, these findings seems to suggest online collective dynamics don't matter.