
Complexity Thoughts: Issue #79
Unraveling complexity: building knowledge, one paper at a time
If you find value in #ComplexityThoughts, consider helping it grow by subscribing and sharing it with friends, colleagues or on social media. Your support makes a real difference.
→ Don’t miss the podcast version of this post: click on “Spotify/Apple Podcast” above!
Foundations of network science and complex systems
Normalized mutual information is a biased measure for classification and community detection
This is bad news (well, actually quite good to know) for network science.
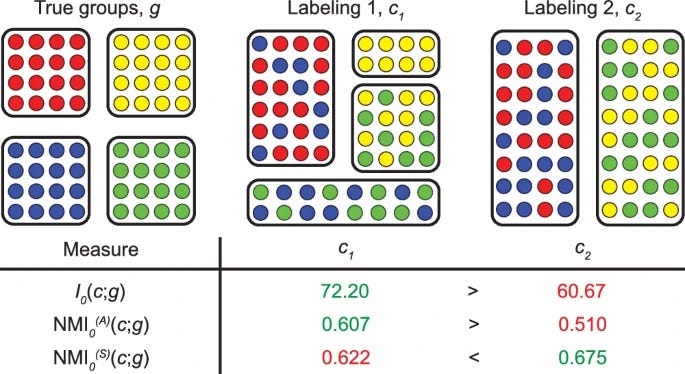
Normalized mutual information is widely used as a similarity measure for evaluating the performance of clustering and classification algorithms. In this paper, we argue that results returned by the normalized mutual information are biased for two reasons: first, because they ignore the information content of the contingency table and, second, because their symmetric normalization introduces spurious dependence on algorithm output. We introduce a modified version of the mutual information that remedies both of these shortcomings. As a practical demonstration of the importance of using an unbiased measure, we perform extensive numerical tests on a basket of popular algorithms for network community detection and show that one’s conclusions about which algorithm is best are significantly affected by the biases in the traditional mutual information.
Correlated quantum machines beyond the standard second law
More surprises from the quantum world, this time about violation of the second law of thermodynamics for classical systems.
This paper presents generalized thermodynamic laws showing that atomic-scale heat engines can turn not only heat but also quantum correlations between particles into useful work. Because these correlations act as an extra energy resource (which are absent from classical theory!) strongly correlated molecular engines could deliver more work than classical predictions and appear to exceed the usual Carnot efficiency bound. Beyond foundational physics, this could also enable highly efficient quantum engines for precision tasks, with potential applications in nanorobotics, targeted drug delivery, atom-by-atom manufacturing and advanced nanotechnology.
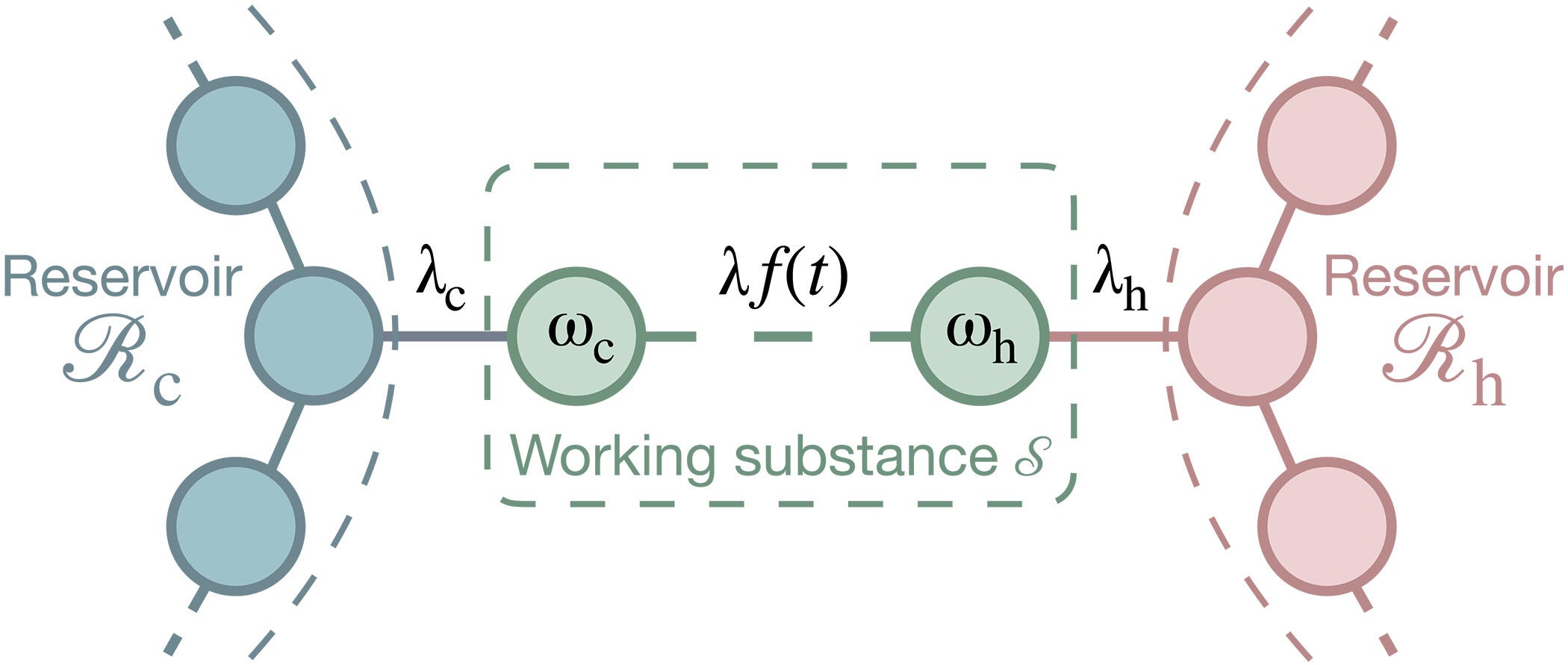
The laws of thermodynamics strongly restrict the performance of thermal machines. Standard thermodynamics, initially developed for uncorrelated macroscopic systems, does not hold for microscopic systems correlated with their environments. We here derive an exact formula for the efficiency of any cyclically driven quantum engine by using generalized laws of quantum thermodynamics that account for all possible correlations between all involved parties, including initial correlations. Furthermore, we demonstrate the existence of two basic modes of engine operation: the usual thermal case, where heat is converted into work, and an athermal regime, where work is extracted from entropic resources, such as system-bath correlations. In the latter regime, the efficiency is not bounded by the usual Carnot formula. Our results provide a unified formalism to determine the efficiency of correlated microscopic quantum machines.
Biological Systems, Complexity & Consciousness
On biological and artificial consciousness: A case for biological computationalism
The paper tries to resolve a key ambiguity in consciousness debates: “computation” in brains is not the same as computation in standard digital machines. It argues that living brains compute through tightly coupled processes across many scales (molecules → cells → networks) under strict energy limits, mixing continuous signals (fields, gradients, oscillations) with discrete spikes. This helps explaining why conscious processing may depend on biology’s substrate and multiscale organization rather than only on abstract information flow.
I must agree, part of this take can be found also in my recent paper on decoding the architecture of living systems (for which a dedicated series of post is planned).
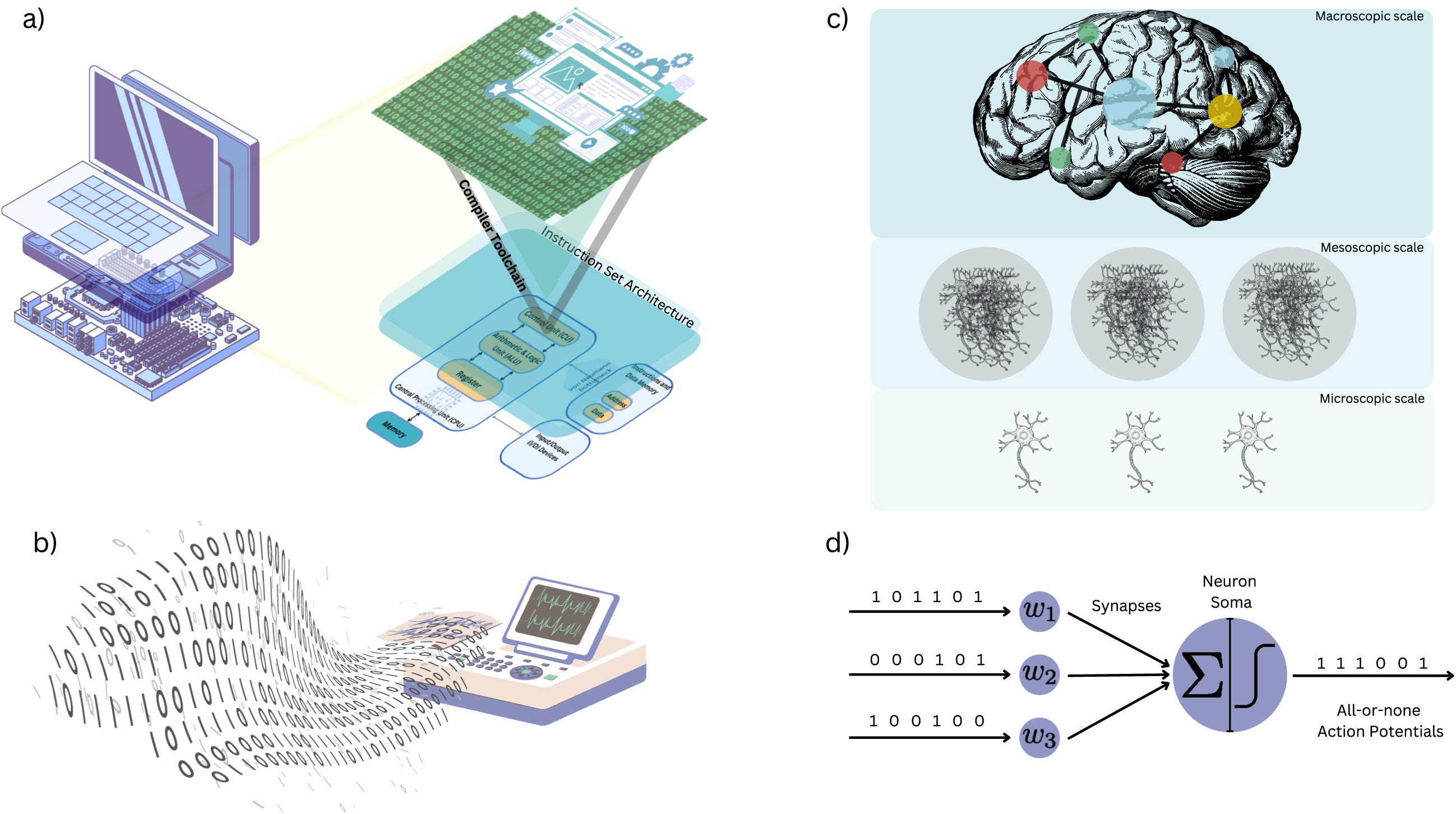
At the same time, the paper clarifies why today’s AI (including LLMs) is unlikely to be conscious even if it imitates intelligent behavior: current systems run on architectures designed to separate hardware/software and scales, and they mostly approximate continuous dynamics rather than physically realizing them. The relevance is practical: if one aims for artificial consciousness, scaling existing digital models may be insufficient; instead, one would need new “hybrid” substrates/architectures that integrate continuous dynamics, real-time multiscale coupling, and energy-like constraints more like brains.
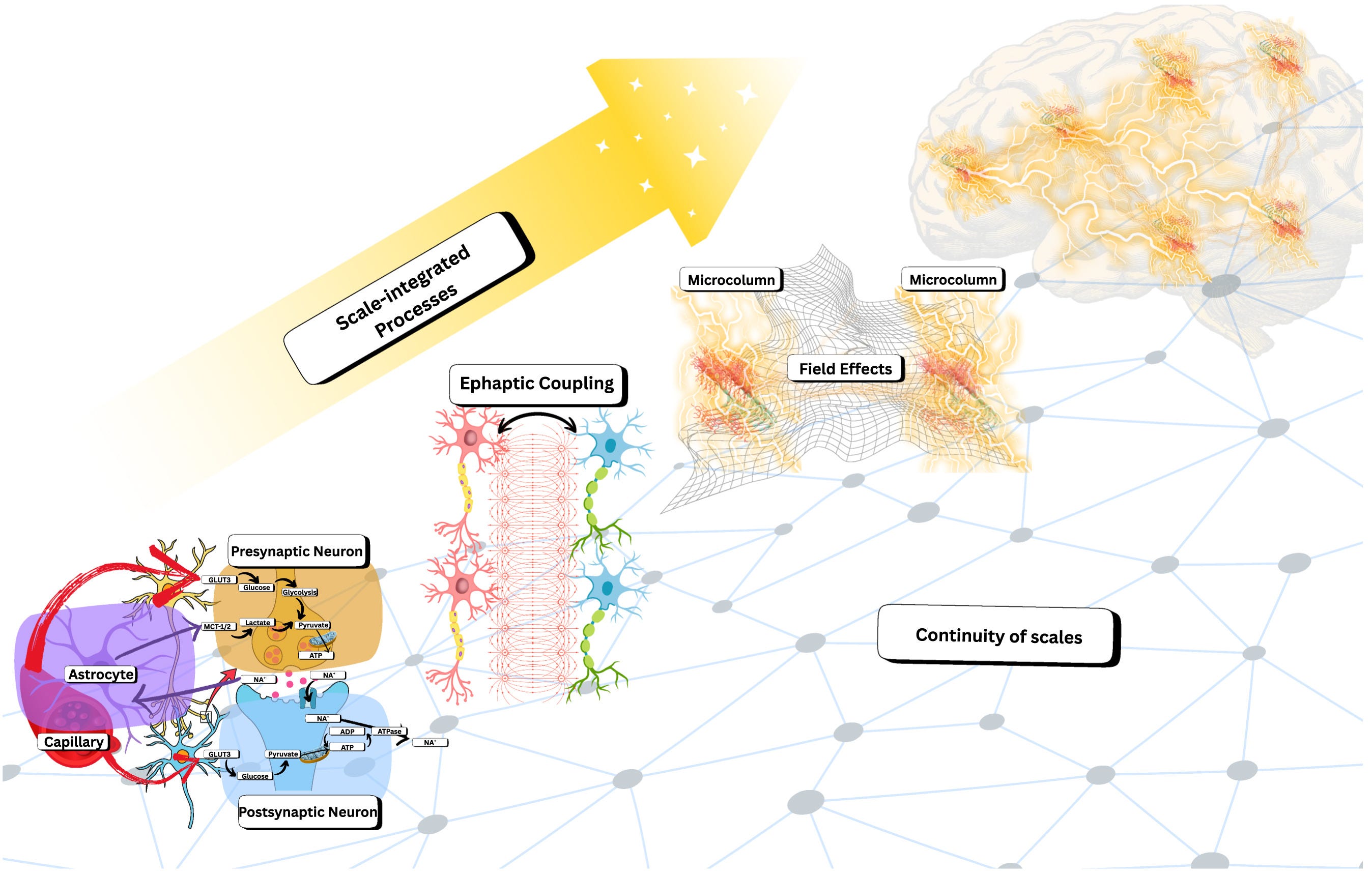
The rapid advances in the capabilities of Large Language Models (LLMs) have galvanised public and scientific debates over whether artificial systems might one day be conscious. Prevailing optimism is often grounded in computational functionalism: the assumption that consciousness is determined solely by the right pattern of information processing, independent of the physical substrate. Opposing this, biological naturalism insists that conscious experience is fundamentally dependent on the concrete physical processes of living systems. Despite the centrality of these positions to the artificial consciousness debate, there is currently no coherent framework that explains how biological computation differs from digital computation, and why this difference might matter for consciousness. Here, we argue that the absence of consciousness in artificial systems is not merely due to missing functional organisation but reflects a deeper divide between digital and biological modes of computation and the dynamico-structural dependencies of living organisms. Specifically, we propose that biological systems support conscious processing because they (i) instantiate scale-inseparable, substrate-dependent multiscale processing as a metabolic optimisation strategy, and (ii) alongside discrete computations, they perform continuous-valued computations due to the very nature of the fluidic substrate from which they are composed. These features – scale inseparability and hybrid computations – are not peripheral, but essential to the brain’s mode of computation. In light of these differences, we outline the foundational principles of a biological theory of computation and explain why current artificial intelligence systems are unlikely to replicate conscious processing as it arises in biology.
Cognition is an emergent property
This paper comes from an interesting special issue on cognitive flexibility.
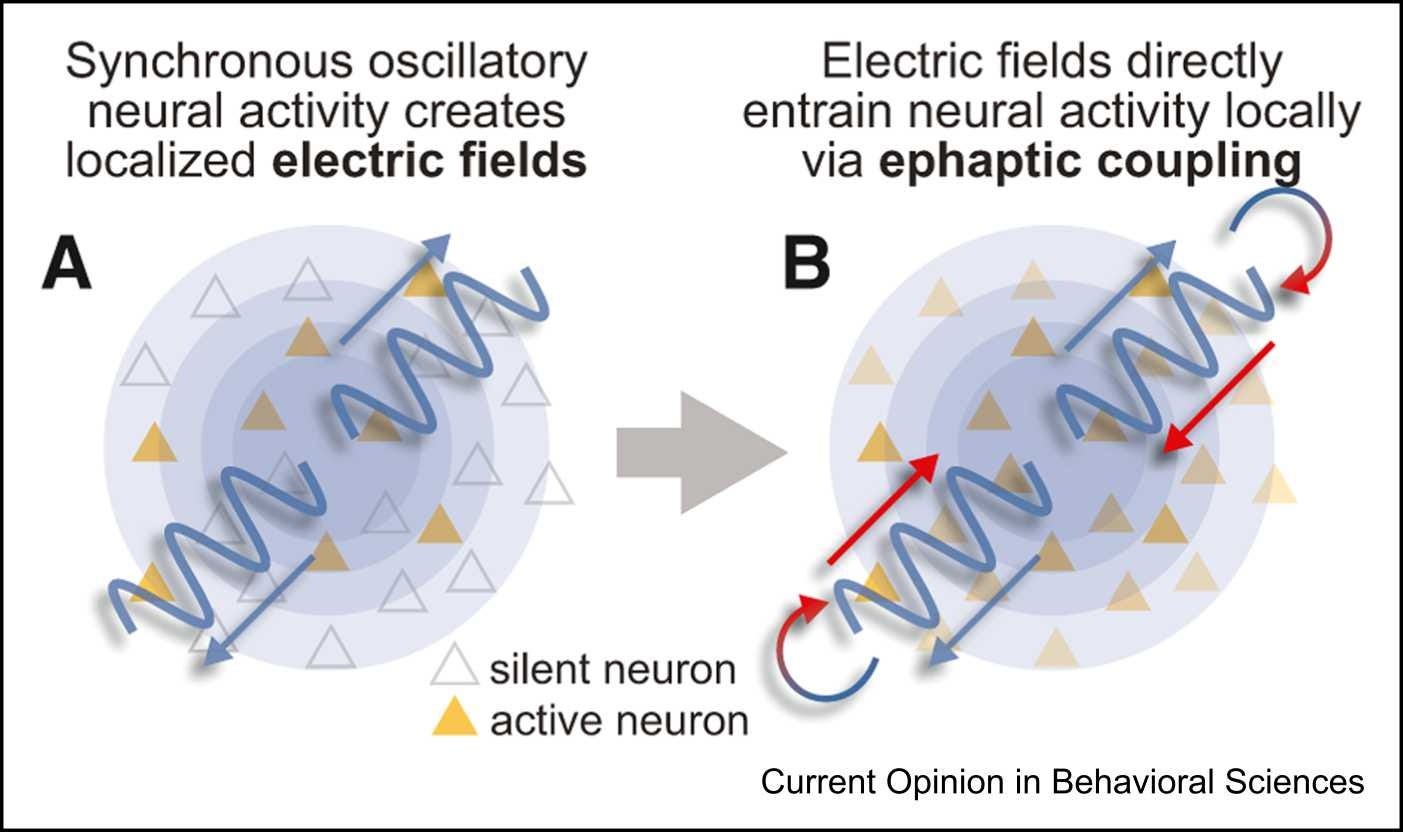
Cognition relies on the flexible organization of neural activity. In this discussion, we explore how many aspects of this organization can be described as emergent properties, not reducible to their constituent parts. We discuss how electrical fields in the brain can serve as a medium for propagating activity nearly instantaneously, and how population-level patterns of neural activity can organize computations through subspace coding.
Artificial Intelligence & Bio-inspired computing
Leveraging network motifs to improve artificial neural networks
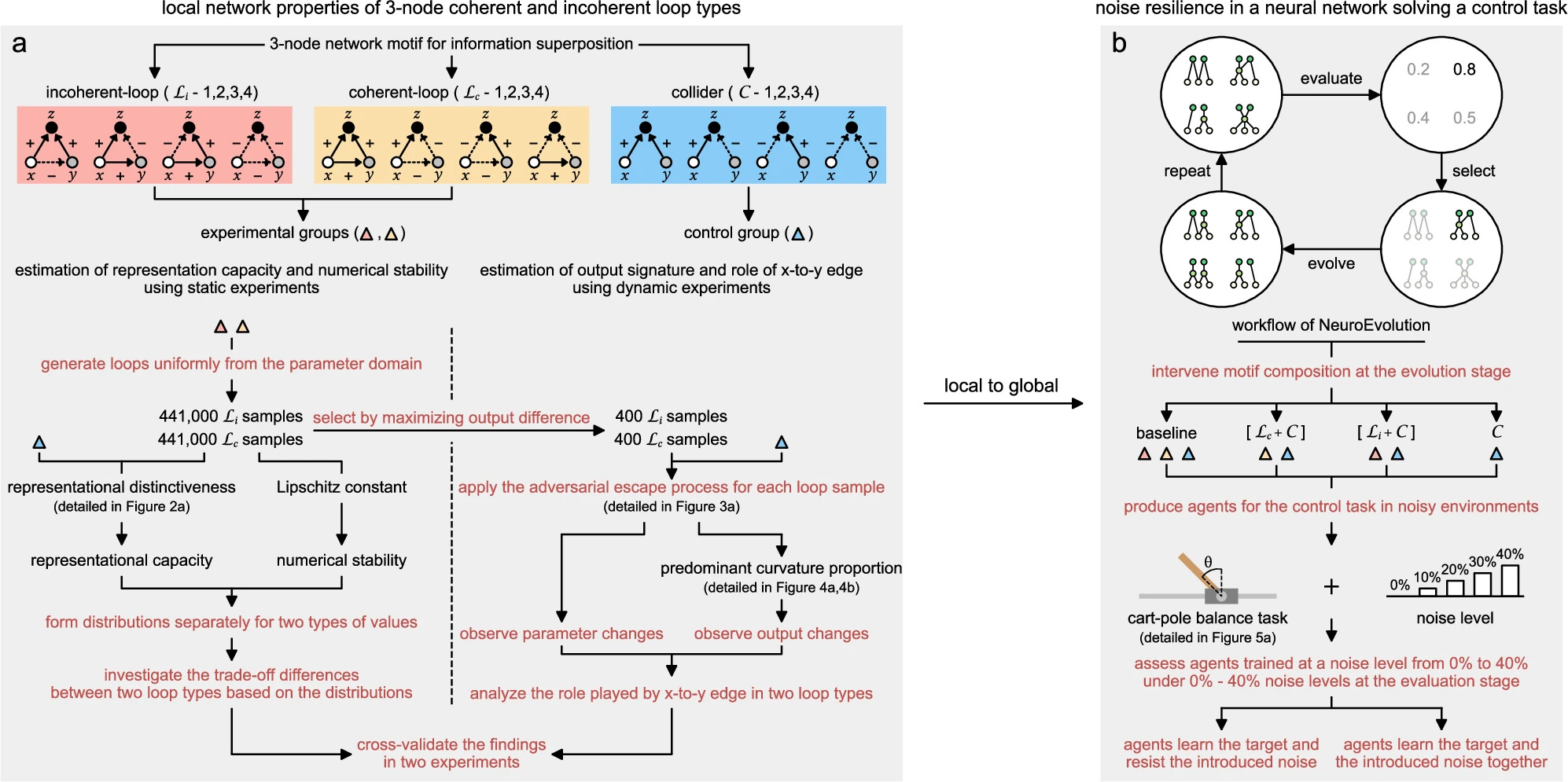
As the scale of artificial neural networks continues to expand to tackle increasingly complex tasks or improve the prediction accuracy of specific tasks, the challenges associated with computational demand, hyper-parameter tuning, model interpretability, and deployment costs intensify. Addressing these challenges requires a deeper understanding of how network structures influence network performance. Here, we analyse 882,000 motifs to reveal the functional roles of incoherent and coherent three-node motifs in shaping overall network performance. Our findings reveal that incoherent loops exhibit superior representational capacity and numerical stability, whereas coherent loops show a distinct preference for high-gradient regions within the output landscape. By avoiding such gradient pursuit, incoherent loops sustain more stable adaptation and consequently greater robustness. This mechanism is evident in 97,240 fixed-network training experiments, where coherent-loop networks consistently prioritized high-gradient regions during learning, and is further supported by noise-resilience analyses – from classical reinforcement learning tasks to biological, chemical, and medical applications – which demonstrate that incoherent-loop networks maintain stronger resistance to training noise and environmental perturbations. This work shows the functional impact of structural motif differences on the performance of artificial neural networks, offering foundational insights for designing more resilient and accurate networks.
Concept transfer of synaptic diversity from biological to artificial neural networks
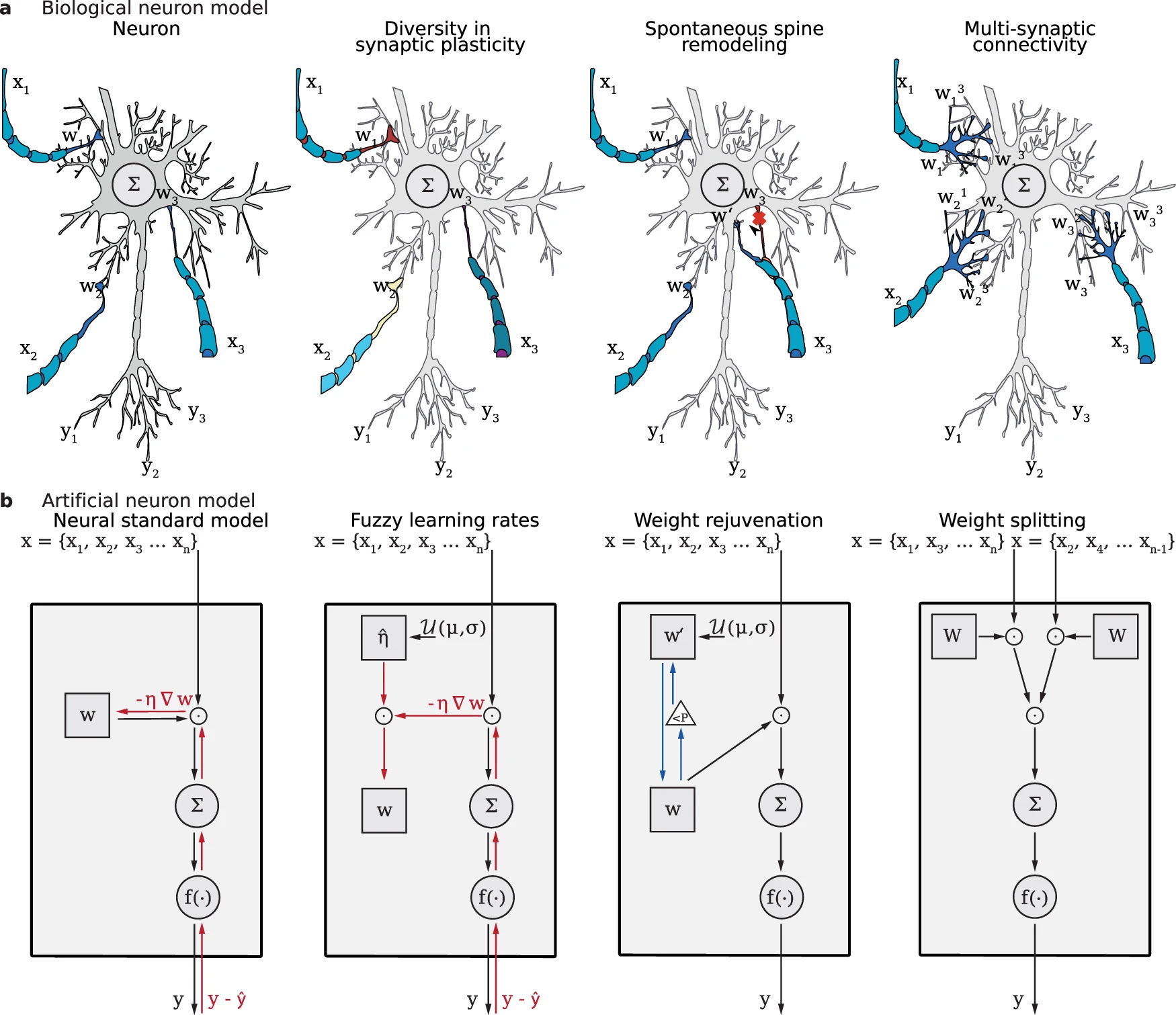
Recent developments in artificial neural networks have drawn inspiration from biological neural networks, leveraging the concept of the artificial neuron to model the learning abilities of biological nerve cells. However, while neuroscience has provided new insights into the mechanisms of biological neural networks, only a limited number of these concepts have been directly applied to artificial neural networks, with no guarantee of improved performance. Here, we address the discrepancy between the inhomogeneous and dynamic structures of biological neural networks and the largely homogeneous and fixed topologies of artificial neural networks. Specifically, we demonstrate successful integration of concepts of synaptic diversity, including spontaneous spine remodeling, synaptic plasticity diversity, and multi-synaptic connectivity, into artificial neural networks. Our findings reveal increased learning speed, prediction accuracy, and resilience to gradient inversion attacks. Our publicly available drop-in replacement code enables easy incorporation of these proposed concepts into existing networks.
Kolmogorov-Arnold Networks Meet Science
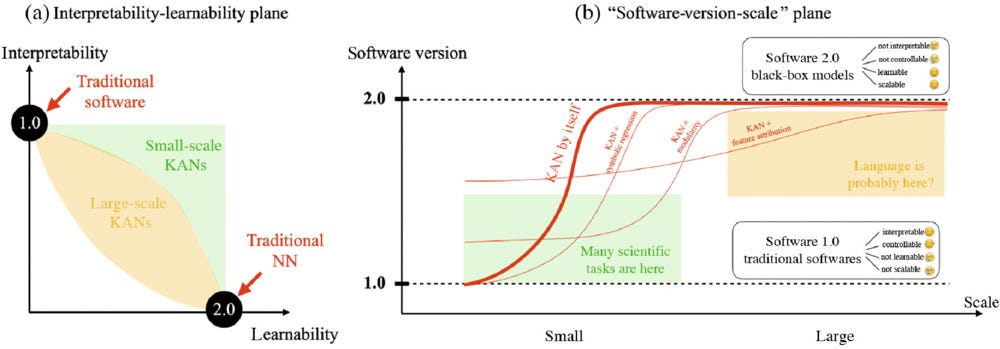
A major challenge of AI plus science lies in its inherent incompatibility: Today’s AI is primarily based on connectionism, while science depends on symbolism. To bridge the two worlds, we propose a framework to seamlessly synergize Kolmogorov-Arnold networks (KANs) and science. The framework highlights KANs’ usage for three aspects of scientific discovery: identifying relevant features, revealing modular structures, and discovering symbolic formulas. The synergy is bidirectional: science to KAN (incorporating scientific knowledge into KANs), and KAN to science (extracting scientific insights from KANs). We highlight major new functionalities in pykan: (1) MultKAN, KANs with multiplication nodes, (2) kanpiler, a KAN compiler that compiles symbolic formulas into KANs; (3) tree converter, convert KANs (or any neural networks) into tree graphs. Based on these tools, we demonstrate KANs’ capability to discover various types of physical laws, including conserved quantities, Lagrangians, symmetries, and constitutive laws.
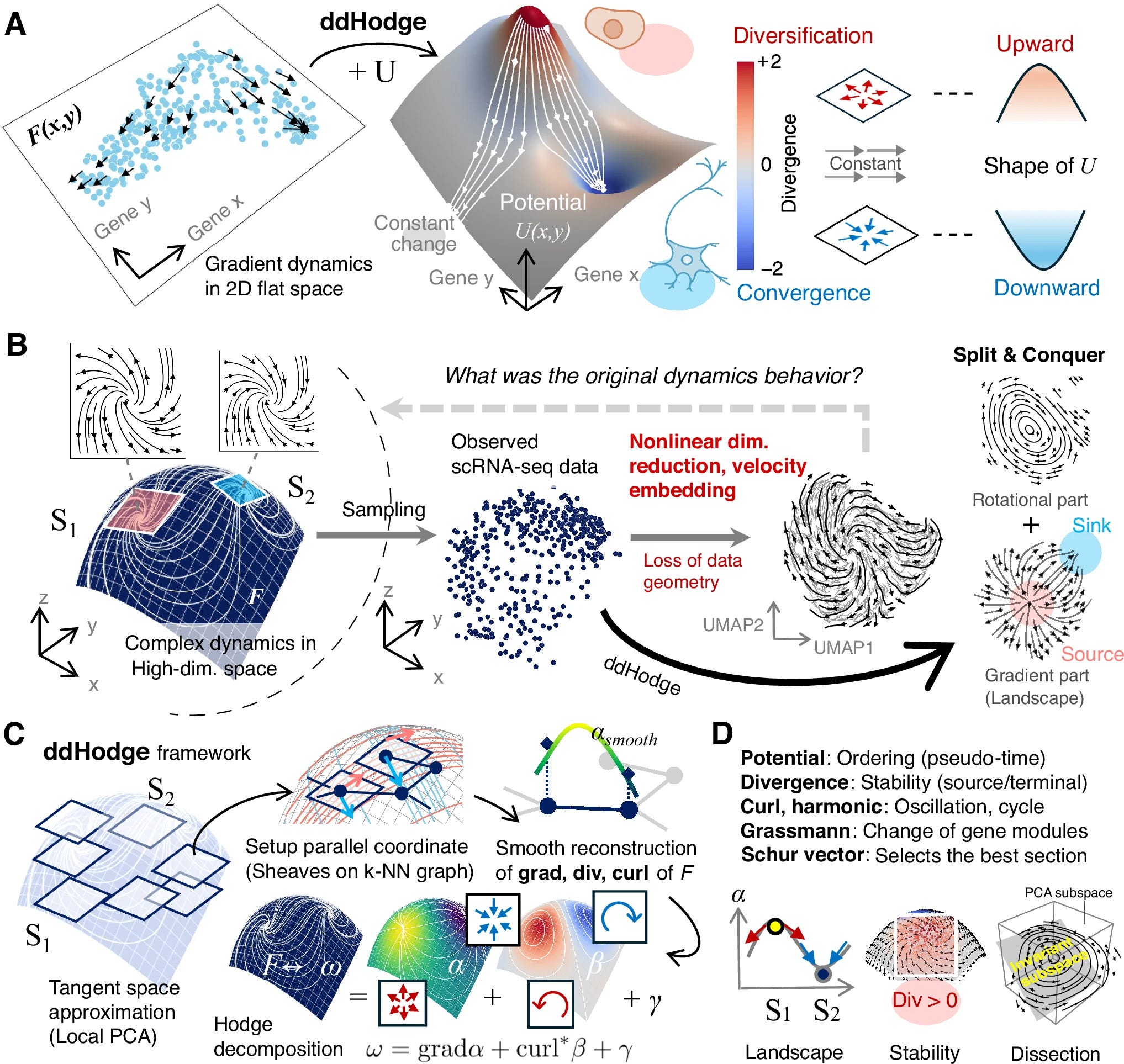
The differentiation potency of cells is governed by dynamic changes in gene expression, which can be inferred from single-cell RNA sequencing (scRNA-seq) data. While velocity-based approaches have been used to analyze cell state changes as vector fields, extracting acceleration (change of change) information remains challenging because of the sparsity and high-dimensionality of the data. Here, we develop ddHodge, a framework based on Hodge decomposition for precise vector-field reconstruction. ddHodge accurately recovers all basic components of the vector field, namely, the gradient, curl, and divergence, including the acceleration of the cell state, as second-order derivatives, even from biased and sparse samples. Furthermore, we extend the method to approximate high-dimensional gene expression dynamics on lower-dimensional data manifolds. By applying ddHodge to scRNA-seq data from mouse embryogenesis, we reveal that the gene expression dynamics during development follow a gradient system shaped by potential landscapes, which has not previously been validated with real data. Furthermore, we quantify differentiation potency as cell state stability on the basis of the divergence and identify key genes that drive potency. Our general computational framework for analyzing complex biological systems can elucidate cell fate decisions in developmental processes.
→ Please, remind that if you find value in #ComplexityThoughts, you might consider helping it grow by subscribing, or by sharing it with friends, colleagues or on social media. See also this post to learn more about this space.