
Complexity Thoughts: Issue #80
Unraveling complexity: building knowledge, one paper at a time

If you find value in #ComplexityThoughts, consider helping it grow by subscribing and sharing it with friends, colleagues or on social media. Your support makes a real difference.
→ Don’t miss the podcast version of this post: click on “Spotify/Apple Podcast” above!
Foundations of network science and complex systems
“We cannot understand what is happening until we learn to think of probability distributions in terms of their demonstrable information content” — Jaynes, 2003
We typically observe large-scale outcomes that arise from the interactions of many hidden, small-scale processes. Examples include age of disease onset, rates of amino acid substitutions and composition of ecological communities. The macroscopic patterns in each problem often vary around a characteristic shape that can be generated by neutral processes. A neutral generative model assumes that each microscopic process follows unbiased or random stochastic fluctuations: random connections of network nodes; amino acid substitutions with no effect on fitness; species that arise or disappear from communities randomly. These neutral generative models often match common patterns of nature. In this paper, I present the theoretical background by which we can understand why these neutral generative models are so successful. I show where the classic patterns come from, such as the Poisson pattern, the normal or Gaussian pattern and many others. Each classic pattern was often discovered by a simple neutral generative model. The neutral patterns share a special characteristic: they describe the patterns of nature that follow from simple constraints on information. For example, any aggregation of processes that preserves information only about the mean and variance attracts to the Gaussian pattern; any aggregation that preserves information only about the mean attracts to the exponential pattern; any aggregation that preserves information only about the geometric mean attracts to the power law pattern. I present a simple and consistent informational framework of the common patterns of nature based on the method of maximum entropy. This framework shows that each neutral generative model is a special case that helps to discover a particular set of informational constraints; those informational constraints define a much wider domain of non-neutral generative processes that attract to the same neutral pattern.
Closing the loop: how semantic closure enables open-ended evolution?
There is a missing link in origin-of-life theories: how “instructions” (like genes) can naturally arise from chemistry and start controlling the machinery that interprets them. By extending a standard self-manufacturing cell model to include time, sensing, and response, it provides an explanation for how systems shift from mere reactions to self-replication plus meaningful control, that is a prerequisite for open-ended evolution and robust adaptation.
This study explores the evolutionary emergence of semantic closure—the self-referential mechanism through which symbols actively construct and interpret their own functional contexts—by integrating concepts from relational biology, physical biosemiotics and ecological psychology into a unified computational enactivism framework. By extending Hofmeyr’s (Fabrication, Assembly) systems—a continuation of Rosen’s (Metabolism, Repair) systems—with a temporal parametrization, we develop a model capable of capturing critical properties of life, including autopoiesis, anticipation and adaptation. Our stepwise model traces the evolution of semantic closure from simple reaction networks that recognize regular languages to self-constructing chemical systems with anticipatory capabilities, identifying self-reference as necessary for robust self-replication and open-ended evolution. Such a computational enactivist perspective underscores the essential necessity of implementing syntax–pragmatic transformations into realizations of life, providing a cohesive theoretical basis for a recently proposed trialectic between autopoiesis, anticipation and adaptation to solve the problem of relevance realization. Thus, our work opens avenues for new models of computation that can better capture the dynamics of life, naturalize agency and cognition and provide fundamental principles underlying biological information processing.
The dynamics of correlated novelties
Loosely speaking, the adjacent possible consists of all those things (depending on the context, these could be ideas, molecules, genomes, technological products, etc.) that are one step away from what actually exists and hence can arise from incremental modifications and recombinations of existing material. Whenever something new is created in this way, part of the formerly adjacent possible becomes actualized and is therefore bounded in turn by a fresh adjacent possible.
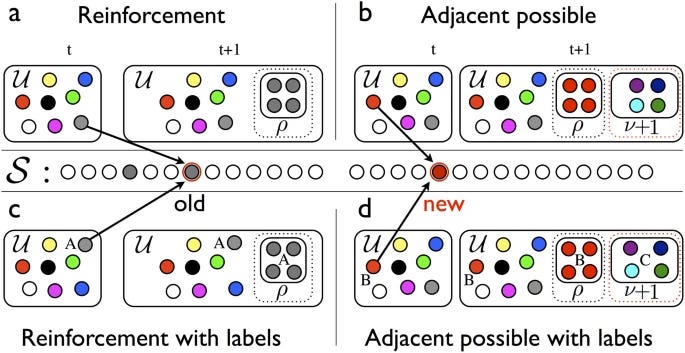
Novelties are a familiar part of daily life. They are also fundamental to the evolution of biological systems, human society and technology. By opening new possibilities, one novelty can pave the way for others in a process that Kauffman has called “expanding the adjacent possible”. The dynamics of correlated novelties, however, have yet to be quantified empirically or modeled mathematically. Here we propose a simple mathematical model that mimics the process of exploring a physical, biological, or conceptual space that enlarges whenever a novelty occurs. The model, a generalization of Polya’s urn, predicts statistical laws for the rate at which novelties happen (Heaps’ law) and for the probability distribution on the space explored (Zipf’s law), as well as signatures of the process by which one novelty sets the stage for another. We test these predictions on four data sets of human activity: the edit events of Wikipedia pages, the emergence of tags in annotation systems, the sequence of words in texts and listening to new songs in online music catalogues. By quantifying the dynamics of correlated novelties, our results provide a starting point for a deeper understanding of the adjacent possible and its role in biological, cultural and technological evolution.
Human behavior
Emergence and evolution of social networks through exploration of the Adjacent Possible space
Network Dynamics of Innovation Processes
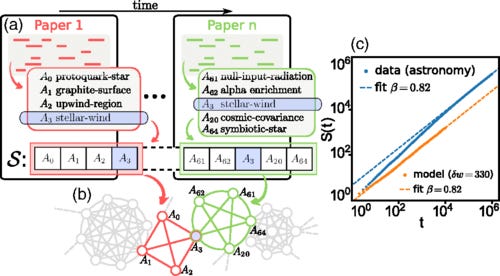
We introduce a model for the emergence of innovations, in which cognitive processes are described as random walks on the network of links among ideas or concepts, and an innovation corresponds to the first visit of a node. The transition matrix of the random walk depends on the network weights, while in turn the weight of an edge is reinforced by the passage of a walker. The presence of the network naturally accounts for the mechanism of the “adjacent possible,” and the model reproduces both the rate at which novelties emerge and the correlations among them observed empirically. We show this by using synthetic networks and by studying real data sets on the growth of knowledge in different scientific disciplines. Edge-reinforced random walks on complex topologies offer a new modeling framework for the dynamics of correlated novelties and are another example of coevolution of processes and networks.
A theory of power-law distributions in financial market fluctuations
Insights into the dynamics of a complex system are often gained by focusing on large fluctuations. For the financial system, huge databases now exist that facilitate the analysis of large fluctuations and the characterization of their statistical behaviour1,2. Power laws appear to describe histograms of relevant financial fluctuations, such as fluctuations in stock price, trading volume and the number of trades3,4,5,6,7,8,9,10. Surprisingly, the exponents that characterize these power laws are similar for different types and sizes of markets, for different market trends and even for different countries—suggesting that a generic theoretical basis may underlie these phenomena. Here we propose a model, based on a plausible set of assumptions, which provides an explanation for these empirical power laws. Our model is based on the hypothesis that large movements in stock market activity arise from the trades of large participants. Starting from an empirical characterization of the size distribution of those large market participants (mutual funds), we show that the power laws observed in financial data arise when the trading behaviour is performed in an optimal way. Our model additionally explains certain striking empirical regularities that describe the relationship between large fluctuations in prices, trading volume and the number of trades.
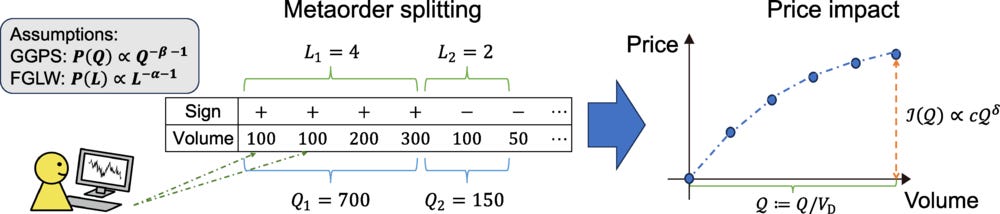
Universal power laws have been scrutinized in physics and beyond, and a long-standing debate exists in econophysics regarding the strict universality of the nonlinear price impact, commonly referred to as the square-root law (SRL). The SRL posits that the average price impact 𝐼 follows a power law with respect to transaction volume 𝑄, such that 𝐼(𝑄)∝𝑄^𝛿 with 𝛿 ≈1/2. Some researchers argue that the exponent 𝛿 should be system specific, without universality. Conversely, others contend that 𝛿 should be exactly 1/2 for all stocks across all countries, implying universality. However, resolving this debate requires high-precision measurements of 𝛿 with errors of around 0.1 across hundreds of stocks, which has been extremely challenging due to the scarcity of large microscopic datasets—those that enable tracking the trading behavior of all individual accounts. Here we conclusively support the universality hypothesis of the SRL by a complete survey of all trading accounts for all liquid stocks on the Tokyo Stock Exchange over eight years. Using this comprehensive microscopic dataset, we show that the exponent 𝛿 is equal to 1/2 within statistical errors at both the individual stock level and the individual trader level. Additionally, we rejected two prominent models supporting the nonuniversality hypothesis: the Gabaix-Gopikrishnan-Plerou-Stanley and the Farmer-Gerig-Lillo-Waelbroeck models [Gabaix et al., Nature (London) 423, 267 (2003).; Q. J. Econ 121, 461 (2006).; Farmer et al., Quant. Finance 13, 1743 (2013)]. Our Letter provides exceptionally high-precision evidence for the universality hypothesis in social science and could prove useful in evaluating the price impact by large investors—an important topic even among practitioners.
Models of social networks based on social distance attachment
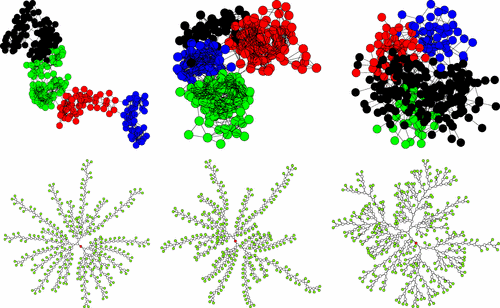
We propose a class of models of social network formation based on a mathematical abstraction of the concept of social distance. Social distance attachment is represented by the tendency of peers to establish acquaintances via a decreasing function of the relative distance in a representative social space. We derive analytical results (corroborated by extensive numerical simulations), showing that the model reproduces the main statistical characteristics of real social networks: large clustering coefficient, positive degree correlations, and the emergence of a hierarchy of communities. The model is confronted with the social network formed by people that shares confidential information using the Pretty Good Privacy (PGP) encryption algorithm, the so-called web of trust of PGP.
Epidemics
Optimal control of spatial diseases spreading in networked reaction–diffusion systems
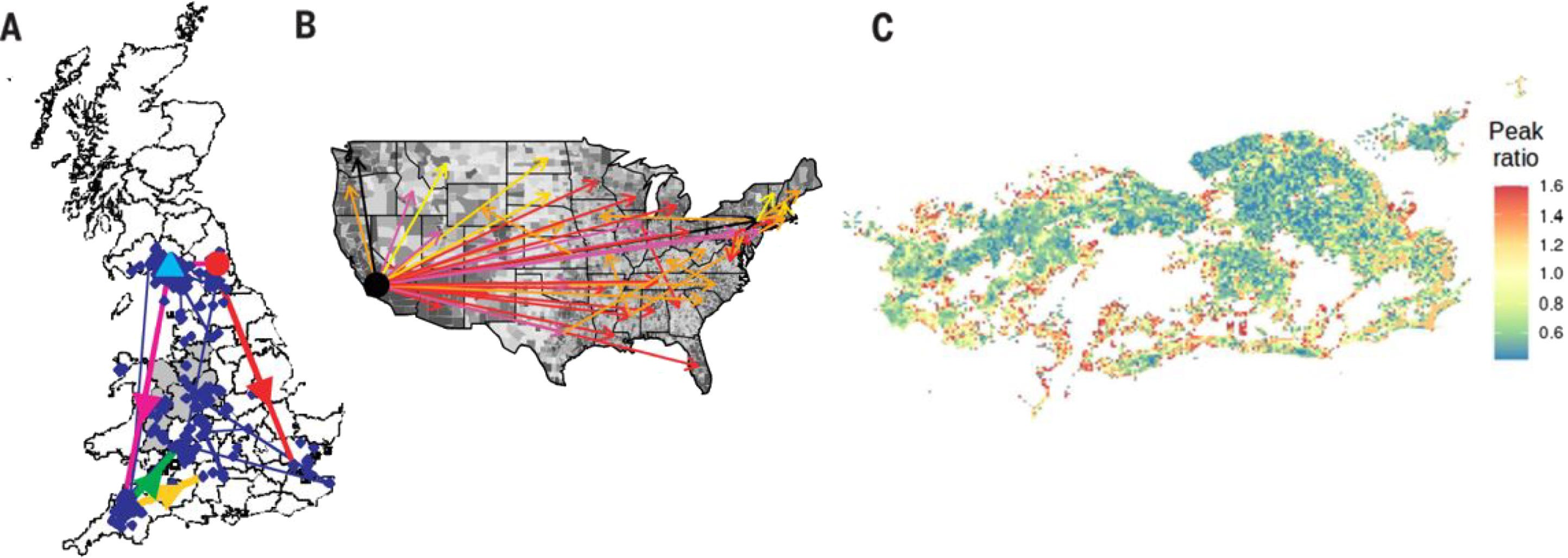
Infectious diseases have long been acknowledged as significant public health menaces by both the general public and health authorities, emphatically underscoring the crucial necessity for highly efficacious prevention and control strategies. Within the realm of statistical physics and complex systems, optimal control theory emerges as a fundamental and indispensable framework for formulating these preventive measures. Simultaneously, networked reaction–diffusion systems have emerged as essential tools for comprehensively understanding the complex dynamics of infectious disease transmission. These systems integrate diverse and essential aspects of human spatial behavior, including habitat distribution, small-world network properties, and large-scale movement patterns, key elements in the in-depth study of complex systems. Consequently, there is a rapidly burgeoning interest in exploring the optimal control problems associated with these reaction–diffusion equations. However, study on the complex dynamics and optimal control of network infectious disease models remains limited, especially in the context of higher-order networks that introduce additional layers of complexity. This article reviews recent advances in the dynamics and optimal control of networked reaction–diffusion systems, underscoring their vital and irreplaceable role in disease prevention and control. We deep dive into the dynamics within both regular and complex networks, investigating how network structure and diffusion parameters influence disease transmission. Furthermore, we comprehensively expound upon several optimal control strategies, including sparse and local optimal control, and propose a comprehensive approach that integrates both reaction and diffusion terms. Finally, we outline future research directions, emphasizing the great potential of integrated strategies to effectively tackle spatial disease transmission, thereby providing a solid theoretical foundation and practical guidance for related fields within the expansive domain of statistical physics and complex systems.
Patterns of human interaction (also known as contact patterns) that impact disease spread can vary depending on age and education level, but less is known about the influence of the economic conditions of the area where people live. In addition, socio-economic information of the contacts (such as income, education or occupation) is often not collected in traditional surveys. In this study, we characterize mixing patterns across different socio-economic groups, even when some information is missing. Using mathematical modeling, we identify which groups generate most infections, and which groups experience the highest disease burden. We also show how diverse contact patterns can determine the success of a control strategy. Our findings can help improve the design of public health measures to contain epidemic spreading.
→ Please, remind that if you find value in #ComplexityThoughts, you might consider helping it grow by subscribing, or by sharing it with friends, colleagues or on social media. See also this post to learn more about this space.