
Spurious patterns and where to find them
Everywhere

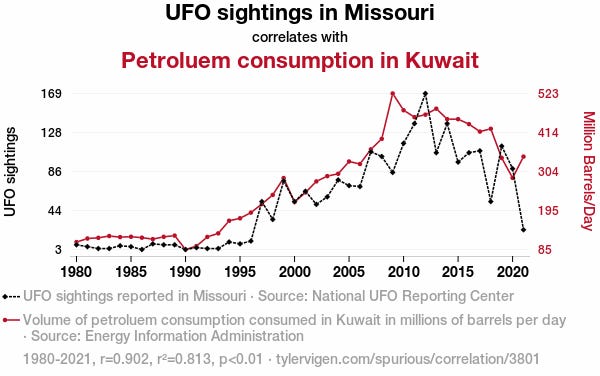
Did you know that the number of UFO sightings in Missouri nearly perfectly correlates with the consumption of petroleum in Kuwait? It can’t be a coincidence and the most plausible explanation is that UFO fuel their starships in Kuwait before taking off. We all know that Kuwait is plenty of petroleum, after all.
But we can do better and ask an AI about ot…
Keep reading with a 7-day free trial
Subscribe to Complexity Thoughts to keep reading this post and get 7 days of free access to the full post archives.